数组可以用来存储一组数据,在内存中,数据分布是连续的。通过循环,可以寻找到符合条件的数据。比如下面这个例子,给定一个info_t数组,和一个目标id,来获取对应的info_t*数据。
typedef struct {
int id;
char* name;
char* email;
} info_t;
info_t*
findInfoById(info_t* infos, int id, int size)
{
for (int i = 0; i < size; i++) {
if (infos[i].id == id) {
return &infos[i];
}
}
return NULL;
}通过这种循环的方式,最好的时间复杂度是O(1),最坏的时间复杂度是O(N),当数组长度,变得很长的时候,循环需要付出巨大的时间代价,才能寻找到目标数据。优化的思路是减少循环的次数,可以对数组排序,然后使用二分查找去搜索目标数据。但在计算机内存变得越来越廉价的现在,还可以通过牺牲一部分空间来换取时间效率的解决方案。那就是哈希表。在某些编程语言中,他还被叫做dict或者是map。
哈希表通过数学运算,将key(这里可以看作上面例子中的id)映射为数组上的一个偏移量,然后将value(可以看作上面例子中的info_t结构体)写入数组,从而完成插入过程,在查找阶段,重复上面的过程,根据id获取偏移量,然后根据偏移量获得数组中的info_t。
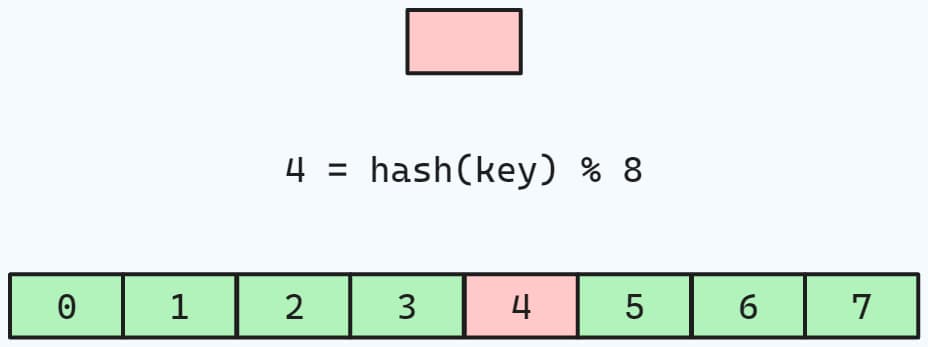
通过数学运算,将原来的循环O(N)的复杂度降为了O(1),大大提高了查找的速度。在内存上,哈希表与数组相比,由于哈希表通过映射操作所获得偏移量是随机的,这也就导致了哈希表中的数据在内存中是分散存储的。同时由于对于不同的key可能会产生相同的偏移量,也就是哈希碰撞导致真实的查找过程中,时间复杂度可能大于O(1),可能是O(2), O(3)。
上面是从理论层面分析了哈希表的大致工作原理,和为什么可以比循环要快的原因。下面将针对上面出现的几个问题逐个分析解决。
如何避免哈希碰撞
哈希表通过offset = hash(key) % length来计算key对应的偏移量offset。最终的offset取决与两部分1. 哈希函数hash(key)和2. 数组长度length。如果哈希函数对不同的key计算的结果一样,那么大概率会获得相同的offset,如果数组长度太短,经过取余操作,也会导致最终的偏移量大概率相同(因为取余得到的结果的范围一定是0到length-1,在哈希函数获得值足够分散的前提下,获得任意一个偏移量的概率是1/(length-1),所以length越小,概率越大,获得相同偏移量的几率也越大),这两种情况,都肯能造成哈希冲突。
哈希表满足下面两个条件,可以尽可能避免哈希冲突
- 选择一个尽可能分散的哈希函数,使得对于不同的key,可以获得不同的结果
- 选择使用一个尽可能长的数组用作映射
到底选择多长的数组
理论上选择一个无限长的数组,在哈希函数足够优秀的前提下,几乎不会发生哈希碰撞,但这样会浪费太多内存。 常见的方法是引入负载系数(loadFactor),即负载系数=存储的数据数/数组长度,通过负载系数,可以不需要i开始就设置一个非常大数组,可以等到空间不够的时候,增加数组长度,使得哈希表始终保持一个内存占用空间和插入查找时间平衡的状态。
如何扩容
扩容后,数组长度发生变化,如果保持原有的数据不动,那么经过新的数组长度取余后,将无法得到正确的偏移量。正确的做法是,申请一个更长的数组,然后将旧数组的数据,通过和之前插入一样的逻辑,重新插入到新的数组上,然后将旧数组丢弃。
哈希碰撞不可避免
尽管前面做了很多努力,尽量避免出现哈希碰撞,但也只是将碰撞的几率减小,并非完全不发生碰撞。如果真的发生了碰撞,又该如何处理插入和查找呢?这里有很多方法,比如线性探测法,二次探测法,再哈希法,链地址法,建立公共缓冲区等等。不管是使用什么方法,只要在插入和查找过程,都遵守相同的规则,那么就可以解决哈希碰撞,这里先介绍第一个线性探测法。
前面讲到,当往哈希表里面插入数据时,会首先通过hash(key) % length获取偏移量,然后根据偏移量的位置,将数据插入到对应的位置,所以,当发生冲突时,即获得的偏移量已经有数据存在,那么就需要寻找一个空闲的位置进行插入。线性探测的意思就是,根据第一次获取偏移量,依次向后寻找(如果到了数组末尾,那么就从头开始寻找)offset = (offset + 1) % length,直到找到一个空闲的位置。这个过程中不用担心找不到,因为有负载系数存在,这就保证了数组中总有空闲位置。负载系数越大,空闲的位置就越多,反之越少。
C语言代码实现
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char* key;
int value;
} HashEntry;
typedef struct {
HashEntry* table;
int size;
int capacity;
float loadFactor;
} HashTable;
int
hashKey(char* key)
{
int hash = 0;
while (*key) {
key++;
hash = (hash << 5) - hash + *key;
}
return hash;
}
HashTable*
createHashTable(int capacity, float loadFactor)
{
HashTable* hashTable = (HashTable*)malloc(sizeof(HashTable));
hashTable->table = (HashEntry*)malloc(sizeof(HashEntry) * capacity);
memset(hashTable->table, 0, sizeof(HashEntry) * capacity);
hashTable->size = 0;
hashTable->capacity = capacity;
hashTable->loadFactor = loadFactor;
return hashTable;
}
void
freeHashTable(HashTable* hashTable)
{
free(hashTable->table);
free(hashTable);
}
static inline void
rehash(HashTable* hashTable)
{
int newCapacity = hashTable->capacity * 2;
HashEntry* newTable = (HashEntry*)malloc(sizeof(HashEntry) * newCapacity);
memset(newTable, 0, sizeof(HashEntry) * newCapacity);
for (int i = 0; i < hashTable->capacity; i++) {
// 跳过不存储数据的位置
if(hashTable->table[i].key == NULL) {
continue;
}
// 将数据插入新的哈希表
int h = hashKey(hashTable->table[i].key);
h = h % newCapacity;
while (newTable[h].key != NULL) {
h = (h + 1) % newCapacity;
}
newTable[h] = hashTable->table[i];
}
// 释放旧的哈希表
free(hashTable->table);
hashTable->table = newTable;
hashTable->capacity = newCapacity;
}
void
set(HashTable* hashTable, char* key, int value)
{
if (hashTable->size >= hashTable->capacity * hashTable->loadFactor) {
// 是否需要扩容
rehash(hashTable);
}
int h = hashKey(key);
h = h % hashTable->capacity;
while (hashTable->table[h].key != NULL) {
// 如果 key 已经存在,则更新 value
if (strcmp(hashTable->table[h].key, key) == 0) {
hashTable->table[h].value = value;
return;
}
// 线性探测
h = (h + 1) % hashTable->capacity;
}
// 插入数据
hashTable->table[h].key = key;
hashTable->table[h].value = value;
hashTable->size++;
}
HashEntry*
get(HashTable* hashTable, char* key)
{
int h = hashKey(key);
h = h % hashTable->capacity;
// 如果遇到空位置,则 key 不存在
while (hashTable->table[h].key != NULL) {
// 找到 key 对应的数据
if (strcmp(hashTable->table[h].key, key) == 0) {
return &hashTable->table[h];
}
h = (h + 1) % hashTable->capacity;
}
return NULL;
}
int
main()
{
HashTable* hashTable = createHashTable(10, 0.75);
char* keys[] = { "a", "b", "c", "d", "e", "f", "g" };
int values[] = { 1, 2, 3, 4, 5, 6, 7 };
#define setKeyValue(key, value) set(hashTable, key, value)
for (int i = 0; i < 7; i++) {
setKeyValue(keys[i], values[i]);
}
#undef setKeyValue
for (int i = 0; i < 7; i++) {
HashEntry* entry = get(hashTable, keys[i]);
if (entry == NULL) {
printf("Key not found\n");
continue;
}
printf("%s: %d\n", entry->key, entry->value);
}
return 0;
}
上面的哈希表只是一个简单实现,只能用于特定的数据类型,如果需要用于任意类型,就需要使用宏定义,或者是void*指针来实现泛型。在对性能要求不高,而且对内存占用要求不高的情况下,使用void*指针可以大大增加代码的可维护性。如果对性能和内存的要求都很严格,那么我推荐你使用宏定义,或者是C++的泛型编程。